UM171 glues to the asymmetric assembly to degrade the CoREST corepressors
PDX tumour immunoblot imaging using the LICOR Odyssey CLX imaging system: donor cells isolated from a mouse cerebellum
The PDX tumour was plated with 1 106 cells per well in Stem cell media after it was isolated from a mouse cerebellum. Cells were immediately dosed with the HDAC1/2 and MLN498, and then placed into a tank with humidity of 80% and CO2 of 5%. After 24h the cells were collected and lysed in a buffer. Immunoblot images were captured using the LICOR Odyssey CLX Imaging system.
High-performance magnetic beads for the digestion and desalination of electrolyte-fixed MV4;11 and SET-2 peptides
MV4;11 and SET-2 (50 million cells per replicate) were treated with 1 µM UM171 or DMSO for 6 h. Cells were washed twice with ice-cold PBS and then frozen in liquid nitrogen until use. Frozen cell pellets were lysed in DPBS (Thermo Fisher Scientific) supplemented with benzonase (Santacruz Biotechnology) and protease inhibitor cocktail (Roche) using a chilled bath sonicator at 4 °C (Q700, QSonica). The lysates were clarified bycentrifugation at 300g. Proteins were quantified by BCA assay (Thermo Fisher Scientific) and normalized to 200 µg per 150 µl. Then, 200 µg of protein was reduced with 5 mM Tris(2-carboxyethyl) phosphine hydrochloride (TCEP) (Sigma-Aldrich) for 2 min and alkylated with 20 mM chloroacetamide (CAA) for 30 min at room temperature. Each sample was added with 1,000 g of magnetic beads as well as a mixture of liquid and reagent to reach final concentration. The samples were then incubated for 30 min with KingFisher Flex system (Thermo Fisher Scientific) at room temperature. The beads were washed three times with 80% high-performance LC (HPLC)-grade ethanol (Sigma-Aldrich) and resuspended with 150 µl of trypsin/Lys-C (4 µg, Thermo Fisher Scientific) in 200 mM EPPS (pH 8.4)/5 mM CaCl2 (Sigma-Aldrich), and proteins were digested overnight for 16 h at 37 °C. Digested peptides were dried by a Speedvac, reconstituted with 5% acetonitrile (Sigma-Aldrich)/0.1% formic acid (Thermo Fisher Scientific) and desalted using Empore C18 Extraction Disks (3 M). Peptides were eluted with 80% acetonitrile/0.1% formic acid, dried by a Speedvac. Peptides reconstituted with 5% acetonitrile/0.1% formic acid were quantified using Quantitative Colorimetric Peptide Assay (Thermo Fisher Scientific) and 10 µg of peptides for each sample were labelled with 50 µg of TMTpro16-plex reagents (Thermo Fisher Scientific) per channel. It took 75 minutes for the reaction to quenched by adding 5% hydroxylamine and 10% formic acid. The samples were dried using a Speedvac.
K–GG Peptide was reconstituted in 3% acetonitrile/0.1% formic acid and 4 l was injected twice on aOrbitrap Exploris 480 mass spectrometer andequipped with FAIMS. The sample was injected onto a capillary column (Picofrit with 10 µm tip opening/75 µm diameter, New Objective, PF360-75-10-N-5) packed in-house with approximately 25 cm C18 silica material (1.5 µm ReproSil-Pur C18, Dr. Maisch) and heated to 50 °C. Peptides were separated at a flow rate of 200 nl min−1 with a linear 154 min gradient from 1.8% solvent B (acetonitrile, 0.1% formic acid), 2 min 5.4% B, 122 min 31.5% B, 130 min 54% B, 133 min 72% B, 144 min 45% B, 149 min 45% B. MS1 spectra were measured with a resolution of 60,000, an AGC target of 100% and a mass range from 350 to 1,800 m/z. Up to 10 MS2 spectra per duty cycle were triggered at a resolution of 45,000, an AGC target of 50%, an isolation window of 0.7 m/z and a normalized collision energy of 32. The FAIMS device was operated in a standard resolution mode using the compensation voltages of 40, 60 and 80 for the first injection followed by a second injection.
The computation of identification and quantification was performed with a search engine. All original target protein sequences were reversed to generate a decoy database that was concatenated to the target database. The JUMP-based matching scores were used to reduce the false discovery rate, which is below 1%, by grouping the PSMs by the ion charge state. If one peptide could be generated from multiple homologous proteins, on the basis of the rule of parsimony, the peptide was assigned to the canonical protein form in the manually curated SwissProt database. The highest PSM number was assigned to the peptide, if no canonical form was defined. We performed the analysis in the following steps, as previously reported, with modifications49: (1) extracting TMT reporter ion intensities of each PSM; (2) correcting the raw intensities on the basis of the isotopic distribution of each labelling reagent (for example, TMT126 generates 91.8%, 7.9% and 0.3% of 126, 127 and 128 m/z ions, respectively); (3) excluding PSMs of very low intensities (for example, minimum intensity of 1,000 and median intensity of 5,000); (4) removing sample loading bias by normalization with the trimmed median intensity of all PSMs; (5) calculating the mean-centred intensities across samples (for example, relative intensities between each sample and the mean); (6) summarizing protein or phosphopeptide relative intensities by averaging related PSMs; (7) finally, deriving protein or phosphopeptide absolute intensities by multiplying the relative intensities by the grand-mean of three most highly abundant PSMs. In addition, we also performed y1 ion-based correction of TMT data. See Supplementary Data 1 for more information.
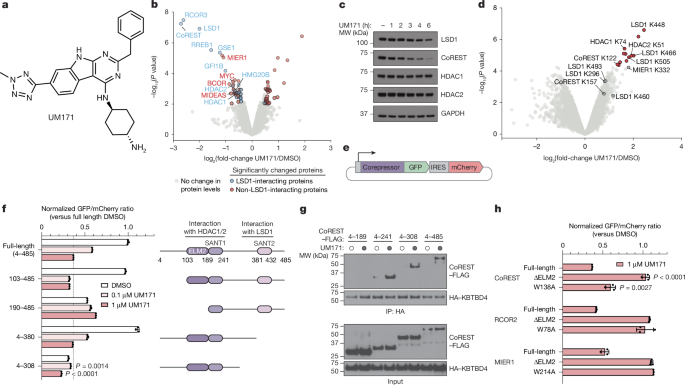
The empirical Bayes-moderated t-test was used to figure out differentially expressedproteins and compare treatment groups. The lower the percentile of the means of the expression, the less likely a small percentage of samples would have low expression. 7,731 of the11,428 coding points were retained for further analysis. Criteria for differential expression included a P value of less than 0.1 and greater than 1.5. The R package ggplot2 was used to create volcano plots. The R environment used was v.4.3.2. PPI networks were constructed using STRINGdb (v.12)51, with a confidence threshold greater than 0.7. The resulting networks were imported and visualized. Text mining, experiments and existing databases were used to source interaction data. See Supplementary Data 1 and 2.
HEK293T cells (Thermo Fisher) were a gift from B. E. Bernstein (Massachusetts General Hospital). There are 293T cells that were given to D. R.Liu by Harvard University. The cells were obtained from a company. All mammalian cell lines were cultured in a humidified 5% CO2 incubator at 37 °C and routinely tested for mycoplasma (Sigma-Aldrich). Stem cell media was used to breed ICB1299, CHLA-01-MED, and MED411FH-TC cells. ICB1299 cells were cultured in Matrigel coated plates while CHLA-01-MED and MED411FH-TC cells were cultured in low-attachment plates. The cells were obtained from the lab. The antibiotics were added with 100 U of penicillin, 100 g of streptomycin (Gibco), and 500 grams of FBS. The cells were cultured in a method called GIBco. HEK293T and Gesicle Producer 293T cells were cultured in DMEM (Gibco) supplemented with 10% FBS. HEK293F cells were cultured in Freestyle 293 Expression Medium (Thermo Fisher) with shaking at 125 rpm. Spodoptera frugiperda (Sf9) insect cells (Expression Systems, catalogue no. 94-001F) were cultured in ESF921 media (Expression Systems) in a non-humidified and non-CO2 incubator at 27 °C with shaking at 140 rpm. The High Five and ExpiSf9 cells were purchased from the company. The Grace insect medium was supplemented with penicillin-streptomycin and 10% of FBS as a result of which cultured at 26 C. All commercial cell lines were authenticated by short tandem repeat profiling (Genetica) and all cell lines were routinely tested for mycoplasma (Sigma-Aldrich).
sgRNAs enriched in the screen were placed as synthetic oligonucleotides and sent into the pRDA_256 plasmid. Lentivirus was produced as described above and transduced into CoREST–GFP K562 cells. After puromycin selection, cells were collected and validated by genotyping. sgRNA sequences, annotations, and primer sequences used for genotyping can be found in Supplementary Tables 3 and 4.
Plasmids were cloned by Gibson Assembly using NEBuilder HiFi (New England Biolabs). NEB Stable was one of the strains used. Final constructs were checked out by a sequencing company.
All KBTBD4 expression plasmids encoded isoform 1 (human, residues 1–518) but longer isoform 2 (residues 1–534) numbering was used. CoREST expression plasmids encoded isoform 1 (human) in either full-length (considered residues 4–485) or various truncations. Open reading frames (ORFs) of human KBTBD4 and RCOR1 (mammalian expression) were obtained from Horizon Discovery. The full-length MIER1 is found in humans. A gift from M.L. Suv was the full-length RCOR2 isoform 1 (human, residues 1–523). The gift was from R. Shiekhattar. E. Verdin gave a full-length HDAC1 ORF. The coding sequence of HDAC2 was made by IDT. The coding sequence of full-length NUDCD3 (human, residues 1–361) was synthesized by Twist Biosciences.
eVLPs were produced as previously described22. In brief, Gesicle Producer 293T cells were seeded in T-75 flasks (Corning) at a density of 5 × 106 cells per flask. A mixture of plasmids expressing the genes VSV-G (400 ng) and MMLVgag–pro-pol (3,300 ng) was produced after twenty-eight hours. After transfection, a producer cellsupernatant was collected at 40–48h forcentrifugation and removal of cell debris. The clarified eVLP-containing supernatant was filtered through a 0.45 μm PVDF filter (Sigma-Aldrich). The filtered supernatant was concentrated by ultracentrifugation using a cushion of 20% (w/v) sucrose (Sigma-Aldrich) in PBS. Ultracentrifugation was performed at 26,000 rpm for 2 h at 4 °C using an SW28 rotor in an Optima XE-90 Ultracentrifuge (Beckman Coulter). The eVLP pellets were resuspended in PBS after being ultracentrifugation. They were stored at 80 C. eVLPs were thaw on ice before being used.
K562 cells were plated for transduction in 96-well plates (Cellstar Greiner Bio-one) at a density of 50,000 cells per well with 5 µg ml−1 polybrene (Santa Cruz) media. The culture media have base editor added directly to them. After 6 h, fresh medium of 50 l was added, and after 48 h more media was added. 72 h after the transduction, the cellulargenomic DNA was isolated and then genotyped. After 7–10 days, cells were allowed to recover.
For cell viability assays, ICB1299, CHLA-01-MED and MED411FH-TC were transduced with eVLPs and cultured in Stem cell media. On day 3, cells were collected for genotyping. Cell viability was measured on day 4 (reference) and day 11 (end point) for ICB1299 and CHLA-01-MED or on day 3 (reference) and day 10 (end point) for MED411FH-TC using Cell Titer-Glo Luminescent Cell Viability Assay 2.0 (Promega) with PHERAstar FSX microplate reader. relative growth was determined by normalized End point readings during 7 days of culture. For immunoblotting, ICB1299 cells were transduced with eVLPs and cultured in Stem cell media for 5 days before collecting for immunoblotting or genotyping. Primers used for genotyping are provided in Supplementary Table 2.
Genomic DNA was extract using the protocol of the manufacturer. We subjected 100 ng of DNA to a first round of PCR (25–28 cycles, Q5 hot start high-fidelity DNA polymerase (New England Biolabs)) to amplify the locus of interest and attach common overhangs. Then, 1 µl of each PCR product was amplified in a second round of PCR (8 cycles) to attach barcoded adapters. Primer sequences are provided in Supplementary Tables 2 and 3. The final amplicons were obtained by gel extract and then their data were put on the illumined MiSeq. The data was processed using the following parameters. 20 –exclude_bp_from_left 0 The excluded item is “bp_from right”. –min_average_read_quality 30 –n_processes 12 –base_editor_output.
The clones were made using the Alt-R andCas9 systems and have ribonucleoprotein complexes. Transfected cells recovered for 72 h before sorting for single-cell clones on the MoFlo Astrios EQ Cell Sorter (Beckman Coulter). Single-cell clones were validated by genotyping and immunoblotting. sgRNA and primer sequences for validation are provided in Supplementary Tables 1 and 2, respectively.
The cells were generated using the same method that was used for the CoREST–GFP cells. Clones of over expression constructs were made using the same techniques that were used to make the pSMAL mCherry. Lentiviral particles carrying the overexpression constructs were produced and used to transduce K562 KBTBD4-null CoREST–GFP cells as described above. At 48 h after transduction, GFP+ percentage was measured for mCherry+ cells in each condition (Supplementary Fig. 1a).
The cells were lysed on ice. The lysates were cleared after supplemented with 1% NP-40 alternative and cOmplete. The protein concentration was quantified as described above and diluted to 1 mg ml−1 in lysis buffer with 1 µM UM171 or DMSO. The supernatants were immunoprecipitated overnight at 4 °C with 25 µl Pierce anti-HA magnetic beads (Thermo Fisher Scientific). The beads were washed six times and eluted in the loading buffer so they could be carried forwards to immunoblotting.
A strain of human cryo-EM structure determination was derived from cells of the Trichoplusia ni High Five. The pFastBac donor and the baculoviruses were constructed using the Bac-to-Bac protocol and reagents. KBTBD4 constructs were tagged on the N terminus with 10×His and MBP tag cleavable by TEV protease. These plasmids were used to prepare separate baculoviruses according to standard protocols (Bac-to-Bac Baculovirus Expression System, Thermo Fisher Scientific). For expression, the monolayer High Five cells were grown to about 80% confluency and co-infected with NUDCD3 baculovirus. The cells were collected and frozen with liquid nitrogen for future purification after being incubated for 72 hours. Cells are resuspended in lysis buffer. Tris-hcl is cold and has a temperature of 150 mM. In addition to 1 mM TCEP, 10 M leupeptin, 1.5 M a proptinin and 1 M pepstatin A were added. The lysates were clarified by centrifugation at 100,000g for 30 min and incubated with amylose affinity resin (New England BioLabs). Resin was washed with lysis buffer, followed by elution using lysis buffer with 10 mM maltose. The eluate was cut with tobacco etch virus protease overnight, followed by the prepacked anion-exchange column (GE Healthcare) to get rid of the protease and further purified by size-exclusion chromatography using the Superdex 200 10/300 GL column (GE Healthcare). The purity of the recombinant protein was verified by SDS–PAGE and fractions with 90–95% purity were pooled and stored at −80 °C.
Recombinant LSD1–CoREST complex comprised LSD1 amino acids 151–852 and CoREST amino acids 308–485. LSD1 amino acids 151–852 were cloned into a pET15b vector (gift from P. A. Cole) containing an N-terminal 6×His-tag using NEBuilder HiFi DNA Assembly Master Mix (NEB, E2621L). After a single colony was grown in 2 YT with 100 percent l1 ampicillin at 37 C, a single colony was expression at an optical density of 600. The plant was grown for 5 h at 25 C. CoREST(308–485) was expressed from a pGEX vector (gift from A. Mattevi). After transformation the plasmid was used to make E. coli cells and a colony was cultivated with a 100 dose ampicillin at 37 C. It was growing overnight at 17 C. The cells were stored at 80 C after being centrifugationd at 4,000g for 30 minutes. All of the purification steps were performed at 4 °C. Pellets of CoREST and LSD1 were resuspended in lysis buffer (50 mM NaH2PO4 pH 8.0, 300 mM NaCl, 5% glycerol, 7.5 mM imidazole supplemented with PMSF, DNase and EDTA-free Roche protease inhibitor cocktail) at a weight ratio of 1:1.5, respectively. Cells were disrupted by sonication, clarified by centrifugation and passed through nickel-affinity resin as before. The eluent was loaded onto theGST and then equilibrated. NaCl, 5% glycerol, 1 mM DTT, 1 mM EDTA) and the GST-tag was cleaved on the resin after incubation with GST-PreScission protease (APEXBIO) overnight at 4 °C. The column was washed with theGST affinity buffer and then gel-screened on a Superdex 200 10/300 GL column equilibrated in a storage buffer. The complex was pooled and stored at 80 C after it was verified that it was pure.
Low- and White-Volume Microtitre Plates in 30l Assay Volume, and 50 nm Dispersion Mixtures for Ubiquitination Studies
Unless otherwise noted, experiments were performed in white, 384-well microtitre plates (Corning, catalogue no. 3572) in 30-μl assay volume, or white, 384-well low-volume microtitre plates (PerkinElmer, catalogue no. 6008280). The data was collected on a Tecan SPARK plate reader with the following settings: 350/50-nm excitation, 4900/1500-nucleus, and 520/500-nucleus emission. The 490/10-Novy and 520/10-Novy Emission channels were acquired using a 50% mirror and a dichroic 510 mirror. The intensity ratio was calculated as 520/490-nanometers on a per-well basis.
Recombinant WT 6×His–KBTBD4 (40 nM), fluorescein-labelled LSD1–CoREST–HDAC complex (40 nM) and CoraFluor-1-labelled anti-6×His IgG (20 nM)33 were diluted into a one-to-one mixture of ligand buffer (50 mM Tris-HCl, pH 8.0, 150 mM NaCl, 1 mM TCEP, 10% glycerol, and a buffer of 20 mM hePES. There were wells of a white, low-volume microtitre plate that were added with or without 100 M SAHA. When UM171 was added in serial dilution it was allowed to equilibrate for a h at room temperature before TR-FRET measurements were taken. Data were background-corrected from wells containing no UM171. Prism 9 was used to fit the data to a four-parameter dose–response curve.
The ubiquitination assays were set up similarly as previously reported67. The total volume was 20 l, and reactions were performed at 37 C. The mixture contained 5 mM of the following: 100 M WT ubiquitin, 100 nM E1, 2 M E2, and 0.5 M neddylatedRBX1–CUL3. 10 M171/DMSO with 25 mM is indicated by WT KBTBD4. Tris-HCl (pH 7.5), 20 mM There is a reaction buffer of 10 M InsP6 and 2.5 mM Magnesium dioxide. Substrate fluorescein–LHC at 0.5 µM was preincubated with everything except E1 in the reaction mixture at 37 °C for 5 min before adding E1 to initiate the reaction. Adding a buffer containing a reducing agent quenched the reactions. The reaction samples were resolved on SDS–PAGE gels and analysed by Colloidal Blue staining and western blotting.
The library of KBTBD4 mutants in the 7-amino acid region between Gly307 and Arg313 was designed to comprise all possible: (1) deletions, (2) 1-amino acid substitutions, (3) 2-amino acid substitutions of adjacent residues, (4) 1-amino acid insertions, (5) 2-amino acid insertions, (6) 3-amino acid insertions of GGG or GSG, and (7) 100 randomly scrambled WT sequences and the 2 remaining MB indels (PR311delinsPPHV, IPR310delinsTTYML). The 5′ and 35′ arms were added as well as forward and reverse barcodes for each of the different sub pools. The libraries were pooled with single-linked oligos ranging in length from 101 to 113 nucleotides, and ordered by Twist Biosciences. The Twist pool was resuspended in tris-EDTA to the concentration of 1 ng μl−1 and the sub pools were separated by PCR amplification of 22 cycles, using lsPCR1 primers listed in Supplementary Table 5 and using 1 ng of the Twist pool as template in each reaction. In Supplementary Table 5, the library and sub pools were amplified with lsPCR2 primers and gel-purified (Zymo Gel DNA Recovery Kit). There were cloned ilogos from the Twist pool and from the Sigma-Aldrich pool.
We analysed data using Python (v.3.9.12) with Biopython (v.1.78), Pandas (v.1.5.1) and NumPy (v.1.23.4). In brief, the raw reads of the matching sequence from unsorted and sorted cells were counted. Counts were then processed by converting them to reads per million, adding a pseudocount of 1 and transforming them by log2. Enrichment of each variant in GFP+ and GFP− populations was quantified by subtracting the GFP+ and GFP− log2-transformed counts, respectively, by corresponding log2-transformed counts for unsorted cells and averaged across replicates (Supplementary Data 4). The heat maps were generated using matplotlib.
The position probability matrices of the GFP+) and unsorted populations were constructed by adding together the raw counts from each category and summing them with the total read counts from each category. The information content was calculated according to the Kullback–Leibler divergence.
where P(N) is the position probability matrix of the GFP+ population for each mutational category, and the position probability matrix of the unsorted population was used as background frequencies BN. Logos were generated using Logomaker (v.0.8)56.
Structural parameters and sensitivity of PDX tumours harbouring WT or CB1572 mutant KBTBD4 to HDAC1/2 inhibitors
MB PDXs harbouring WT KBTBD4 (RCMB28 n = 3, MED411FH n = 2) or KBTBD4-PR mutant (ICB1572 n = 5) were used to assess sensitivity to the HDAC1/2 inhibitor RBC1HI. In brief, the freshly resected PDX tumours were cut into little pieces and put into a papain solution for 30 minutes at 37 C. LS003126) containing N-acetyl-l-cysteine (160 μg ml−1, Sigma-Aldrich, catalogue no. There are two plants, A9125 and Dnase I (12 g ml1, sigma-Aldrich). A gentle pipetting of the single cells separated DN25) from single cells. After 3 min, the cells in the tumour cell suspension were removed by washing them in DPBS-BSA. Cells were filtered using a 40-µm strainer and counted, and viability assessed to be above 80%. Cells were plated at 1,000 cells per well in 384-well plates in Stem cell media. The plated cells were immediately added with a final concentration of 40–0.006 M, and then incubated with DMSO for 72 h. Cell viability at the end of incubation was measured using Cell Titer-Glo Luminescent Cell Viability Assay 2.0 (Promega) with PHERAstar FSX microplate reader. The raw data was converted to cell viabilities, and the data was analysed for half-maximum inhibitory concentration values.
The first structural models of the KBTBD4 dimer were predicted with the help of AlphaFold-Multimer. The structural models of KBTBD4 BTB-BACK domain, KELCH-repeat domain and HDAC1–CoREST were separately fit into the cryo-EM map using UCSF ChimeraX-1.7 (rc2023.12.12)63. The model was further improved thanks to real space refinement and the use of the correct sequence of genes in the model. The structure figures were made using PyMOL67.
There were grids that were glow discharged for 30 s and then 20 s with a glow discharge cleaning system. A freshly glow-discharged grid was applied after 3.0 l of purifiedkbbbd4 with a final concentration of 0.1 n-decyl -d-maltoside. After incubating in the chamber at 10 °C and 100% relative humidity for 60 s, grids were blotted for 3 s with a blotting force of zero, then immediately plunge-frozen in liquid ethane using a Vitrobot Mark IV system (Thermo Fisher Scientific). Data collection was performed on the FEI Titan Glacios transmission electron microscope (Thermo Fisher Scientific) operated at 200 kV at the Arnold and Mabel Beckman Cryo-EM Center of the University of Washington. Automation scheme was implemented using the SerialEM72 software using beam-image shift73 at a nominal magnification of ×105,000, resulting a physical pixel size of 0.885 Å. The images were taken using a K3 camera. The dose rate was set to 10 e− Å−2 s−1, and the total dose of 50 e− Å−2 for each image were fractionated into 99 electron-event representation frames. Data were collected in four sessions with a defocus range of 0.8–1.8 μm. In total, 11,263 videos were collected.
For the KBTBD4–UM171–LHC structure, a total of 10,816 videos were collected and imported into CryoSPARC74 followed by patch motion correction and patch contrast transfer function (CTF) estimation. A total of 10,637 micrographs were retained after being checked by a manual inspection. The blob picker job in CryoSPARC was able to pick over 7 million particles. 928,437 particles were selected and reconstructed after being cleaned by 2D classification. All of the particles were used for this purpose. After one more cleaning up, 186,131 particles were chosen to be re-exported without using a tool called a quadrangle. The overall resolution of 3.93 was helped by the homogeneity and non-uniform refinement75. The two maps provided clearer density for the KBTBD4 protomer A and CoREST. The data processing details are provided in Extended Data Fig. 4.
Enrichment of K–GG Peptides Using a UbiFast Method and a TMT Pro Cloning Method
Enrichment of K-ε-GG peptides was performed using the UbiFast method as previously described57,58. For each sample, 500 µg peptides was reconstituted in 250 µl HS bind buffer (Cell Signaling Technology) with 0.01% CHAPS. The reconstituted peptide was added to the HS anti-K–GG antibody bead in the 96-well KingFisher plate. The plate was covered and put in a bag and put in a freezer for 1 h. The plate containing peptides and anti-K-ε-GG antibody beads was then processed on the KingFisher Flex as previously described57. In brief the bead bound enriched peptide was washed with 50% acetonitrile/50% hss wash buffer and PBS. The K-GG peptides were labelled while on a bead with 400 g of TMTpro reagents for 20 min and then quenched with 2% hydroxylamine. The beads were then washed with HS wash buffer before being deposited into 100 µl PBS. All sample wells were combined, the supernatant was removed and enriched K-ε-GG peptides were eluted from the beads with 2 × 10 min 0.15% TFA. The eluate was desalted using C18 StageTips.
The MIER1 and RCOR2 inserts, which were truncated, were used in the Cilantro 2 eGFP-IRES-mCherry reporter. Point mutations were introduced into coding regions using standard PCR-based site-directed mutagenesis techniques. Deletion constructs were made by PCR amplification of the appropriate regions and cloned into the Cilantro 2 vector using Gibson cloning (New England Biolabs). In order to transduce molm-13 cells, Lentiviral particles carrying the respective constructs were produced and used. Then, 48 h after transduction, cells were selected with 1 µg ml−1 puromycin for 3–5 days. After the cells were treated with various concentrations of UM171, their mCherry and GFP were measured on the avostry 3000RYB. The geometric mean of the ratio of GFP to mCherry was calculated for each sample using a software program. The ratios for the individual drug-treated samples were normalized to the ratios of the DMSO-treated samples in Microsoft Excel (v.16.80) and plotted using GraphPad Prism (v.9.4.0). All degradation assays were done in triplicate and FACS-gating schemes are shown in Supplementary Fig. 1a.
Source: UM171 glues asymmetric CRL3–HDAC1/2 assembly to degrade CoREST corepressors
Synthesis, purification and nucleosome assembly of globular and semisynthetic Histone H3K9ac(C110A) using the Monolith NT.115 system
The Monolith NT.115 system used the NANO BLUE mode for the assays to be performed. The power of the laser was 50% and the power of the MST was medium. KD values were calculated using MO.analysis (v.2.3) software with the quadratic equation binding KD model shown below:
$$AB=\frac{({A}{{\rm{T}}}+{B}{{\rm{T}}}+{K}{{\rm{D}}})-\sqrt{{({A}{{\rm{T}}}+{B}{{\rm{T}}}+{K}{{\rm{D}}})}^{2}-4({A}{{\rm{T}}}{B}{{\rm{T}}})}}{2}$$
The depsipeptide as Fmoc-Thr(OtBu)-glycolic acid was synthesized based on a reported two-step protocol61. Then, H3K9ac(1–34) with a sequence as ARTKQTARKS-TGGKAPRKQL-ATKAARKSAP-A-TOG-G was synthesized by standard solid-phase peptide synthesis and purified by reversed-phase HPLC. The Fmoc-protectedcarboxylic acids were purchased from Novabiochem. F40 sortase was expressed and purified as reported previously, and bacterial expression and purification of Xenopus laevis globular H3 (gH3; amino acids 34–135 C110A) were performed also according to a previous protocol61. The F40-sortase-catalysed histone H3 ligation reaction was done between the gH3 and the H3K9ac. The reaction mixture was purified by ion-exchange chromatography to obtain pure semisynthetic histone H3K9ac (C110A) characterized by MALDI-TOF MS as reported previously62.
146 bp Widom 601 DNA was prepared according to previously reported methods used for the nucleosome reassembly63. The histone H2A, H2B, and H4 of X. laevis were then re-made, followed by the assembly of the histone Octamer. The Nucleosome assembly was used for using 146 bd 510 widom DNA, and the Octamer was used for purification using the Superdex 200 10/300 GL column. The final mixture was subjected to HPLC purification (Waters, 1525 binary pump, 2489 UV-Vis detector) with a TEKgel DEAE ion-exchange column to purify the final nucleosome product. The anti-H3K9ac antibodies were used to analyse the H3k9ac containing nucleosome which was analysed with native TBE-gel and with various stainings.
Source: UM171 glues asymmetric CRL3–HDAC1/2 assembly to degrade CoREST corepressors
High-precision single-cell assay of recombinant HDAC1 and HDAC2 in a white microtitre plate (Corning 3572)
Recombinant HDAC1 (BPS Bioscience 50051) or HDAC2 (BPS Bioscience 50002) were diluted to 6 nM (1.2×) into buffer containing 50 mM HEPES, pH 7.5, 100 mM KCl, 0.5 mg ml−1 BSA, 0.001% Tween-20 and 25 μl added to wells of a white, 384-well microtitre plate (Corning 3572). Test compounds were added in serial dilution (1:2 titration, 15-point, cmax = 10 μM) using a D300 digital dispenser (Hewlett-Packard), and allowed to equilibrate for 1 h at room temperature. Then, 5 μl of 6× MAZ1600 HDAC substrate28 was added (final HDAC1/2 concentration 5 nM; final MAZ1600 concentration 18 μM) and deacetylase activity was allowed to proceed for 45 min at room temperature. A developer solution was added with 150 nMtrypsin and 40 M. The plate was used for 30 min at room temperature. 7-Amino-4-methyl coumarin fluorescence was measured on the Tecan Spark plate reader: 350/20 nm excitation, 460/10 nm emission. The assay floor (background) was defined with the 10 μM LBH589 dose, and the assay ceiling (top) was defined through a no-inhibitor control. Data was background-corrected, normalized, and then fit to a response curve with the help of Prism 9.
sgRNAs enriched in the base editing screens were ordered as synthetic oligonucleotides (Azenta/Genewiz), annealed, and ligated into either pRDA_478 or pRDA_479. The manufacturer’s protocol states that the HEK293T cells were transfectioned using the plasmids. Then, 48 h after transduction, cells were selected with 2 µg ml−1 puromycin (Thermo Fisher Scientific) for 3 days, then sorted for single-cell clones on the BD FACSAria Cell Sorter (BD Biosciences). genotyping and immunoblotting were used to evaluate single-cell clones. sgRNA sequence and annotations are included in the Supplementary Tables 3 and 4.
We tested a null model of random sgRNA enrichment scores to measure the statistical significance of the clusters. The sgRNA enrichment scores were adjusted by LOESS and the per-residue enrichment scores were also adjusted by LOESS. The deduced P values were used to calculate the observed resistance scores and the null distribution of random resistance scores. The FDR was controlled using the Benjamini–Hochberg procedure. Linear clusters were called by identifying all contiguous intervals of glycines with an adjusted P 0.05. For plotting, adjusted P values were increased by a pseudocount of 10−4, log10-transformed and multiplied by −1.
Lentiviral particles carrying overexpression constructs were produced and used totransduce K562 KBTBD4-null CoREST–GFP cells. The particles were added with a final concentration of 40–0.006 M, and then incubated with DMSO for 72 h. The cells were selected with 2 g ml1 puromycin for three days, then sorted for single-cell clones on the BD FACSAria Cell Sorter (BD Biosciences).